JetRacerの速度制御について考えてみた。
この記事について
この記事はAI RC Car アドベントカレンダー 2019 3日目の記事です。3日目の記事はJetRacerの速度制御についてNVIDIAのリポジトリのブランチから考えてみたいと思います。この記事はある程度JetRacerの走行の仕組みを理解されている方向けになります。なるべく補足を入れていきますが、わかりづらい点はご容赦ください。
JetRacerの速度制御の必要性
JetRacerで利用するディープラーニングでは、撮影した画像に対して進行方向を画像上のX,Y座標として教師データを与えていきます。学習したAIモデルは入力画像のX軸方向の座標を出力します。この座標を元にステアリングの制御値を生成する。仕組みです。これだけの仕組みですが、十分にコースに追従した走行が可能となります。
以下、JetRacerリポジトリで公開されている学習の様子です。
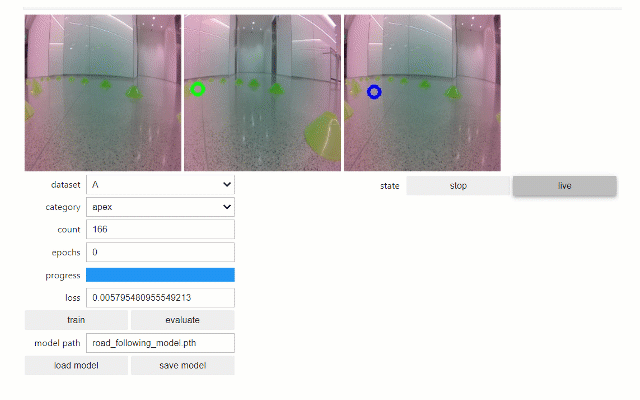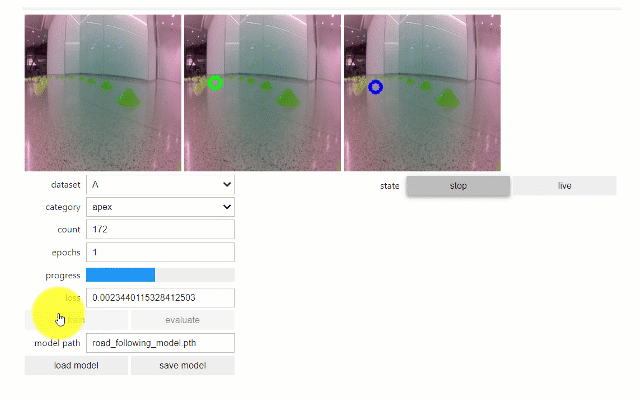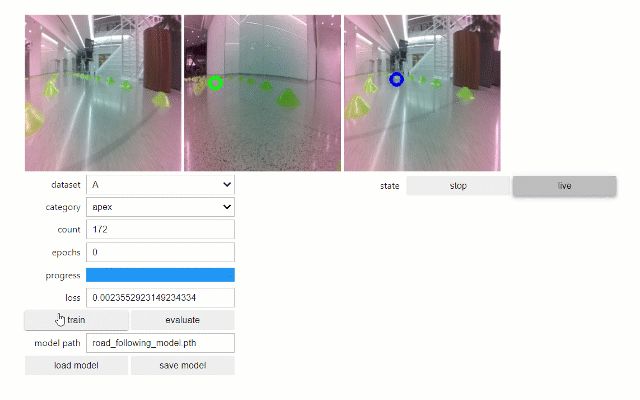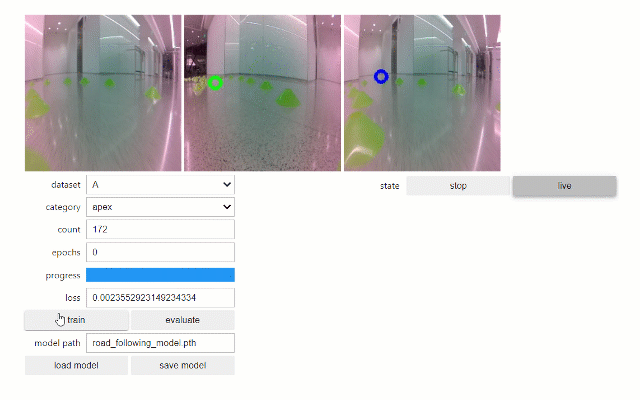
一方で速度についてはパラメータとして与えられ、一定の速度でコース上を周回します。しかし、コースの直線部分もカーブ部分も均一な速度となるため、早すぎるとカーブではコースアウトしやすくなり、遅すぎると全体的に速度が遅くなってしまいます。そのため、JetRacerの速度をいかに最適に設定するかは周回速度を競うために重要な問題となります。
[速度の図]
JetRacerの速度制御方法
速度制御の方法としてもっとも簡単に思いつくのはステアリングの制御値に合わせて速度を加減速させる方法です。制御値の絶対値の大きさに比例して速度を遅くすれば直線部分とカーブ部分で速度のメリハリをつけることができます。全体的に速度を上げて走行させることができるようになります。

しかし、この方法には課題があります。まず、パラメータをヒューリスティックに決めなければいけません。走行させる速度の段階や、ステアリングの値に合わせてどういったルールで速度を落としていくのかを調整しなければいけません。ある程度数式で近似する方法もあれば、IF-THENのルールに落とし込む方法もあるでしょう。何れにしても走行のたびに試行錯誤が必要です。 また、速度の調整が遅れてしまうという問題があります。ステアリングの値が大きくなる時点で車体はすでにカーブに入っています。この時点で速度を落としても車体の慣性により十分に速度を落とすことはできません。実際の車の運転でもカーブ前に十分に速度を落として、。カーブを抜けるとともに速度を上げていく操作をします。ルールベースの方法ではこういったアクセル操作を行うことはできません。
コースの状態を把握しながら速度を加減速するためには、現在撮影している画像からその後のステアリングの状態、先のカーブの状態を推定する必要があります。しかし、現在のコースの状態のみからそれを把握するのは難しくなります。このアクセル操作を実現するためにはいかに、コースの形状を学習させていくかが鍵となりそうです。
circuit_learningに見る速度制御へのディープラーニングの適用
NVIDIAのJetRacerリポジトリにはcircuit_learningと呼ばれるブランチが存在します。これはJetRacerの速度制御をディープラーニングで実現させるサンプルノートブックが含まれています。このブランチのnotebook/circuit_learningフォルダ内がそれです。
GitHub - NVIDIA-AI-IOT/jetracer at circuit_learning
このcircuit_learningは前述のコースの形状を学習させるために工夫が施されています。まず、あらかじめ学習させたステアリングのみを制御するモデルを使いコースを走行します。走行時に、推論したステアリング値をラベルとしてコースの画像を収集します。収集された画像は時系列順に連番が振られています。これが速度制御モデルの学習データとなります。
circuit_learningの学習ではこの学習データを学習しますが、ラベルデータの扱いを工夫しています。N番目の画像のラベルはN+TIMESTEPまでの画像のラベルに係数をかけて足し合わせたものです。この時、係数は指数的に値が小さくなる関数を設定します。これは画像の枚数が増えるにつれて、値が小さくなるようにする工夫です。ここの画像のラベルは前述の通り、ステアリング値です。先のステアリング値を見ていくことで、将来、コースがどう変化するかを見ています。さらに指数的に変化する係数をかけることで、よりコースの近い状態が影響が大きくなるようにしているようです。つまり、カーブが近づくにつれて値が大きくなるラベルを設定することができます。実際のコードはtrain_model.pyのCircuitDatasetクラスで実現しています。
コード上からラベルづけに関係する部分を抜粋すると以下のようになります。
# 重みの作成、num_timestepsは先読みする枚数が設定されている。 gain = torch.exp(-3e-2*torch.linspace(0.0, num_timesteps, num_timesteps)) # ラベルをつける画像からnum_timesteps枚分のラベルを取得する。 for i in range(self.num_timesteps): path = os.path.splitext(os.path.basename(self.image_paths[idx + i]))[0] x = float(int(path.split('_')[1]) - 50) / 50.0 target[i] = x # 重みをかけて正規化し、総和を取る label = torch.sum(self.gain * torch.abs(target) / torch.sum(self.gain), dim=0, keepdim=True)
上記を学習させると、カーブが近づくにつれて出力される値は「大きく」なります。そのため、実際に速度制御に使う場合は逆数を取るなど工夫が必要です。サンプルではlive.demo.ipynbで速度をcar.throttle = np.exp(-15*out) * speed_gain.value + speed_offset.valueと計算しています。ここでoutは推論結果の出力です。
まとめ
この方法で速度制御をしっかりできるようになりましたと記載できればかっこいいのですが、今現在これで本当に速度が制御できるかわかっていません。何度かテストデータに対して推論を行い、速度変化をシミュレートしてましたが、思うような結果が出ていません。また、計算に使う画像の枚数や、ラベル計算式のハイパーパラメーターなど依然としてヒューリスティックな部分が残っているのも気になります。大きな方針としては良いのでしょうがまだまだ改良が必要です。引き続き、色々試してみたいと思います。
ソラコムのイベントでLTしたらSORACOM Lagoonがパワーアップした話
この記事について
この記事はSORACOM Advent Calendar 2019 2日目の記事なります。今回は年末振り返りを考えてLT発表はしたけどブログ記事にしてなかった内容を紹介します。元ネタの資料は以下。4月に行われたSORACOM Drunkup でLTさせていただいた内容です。実はタイトルの通り、このLTの最後に提案した機能が先日Lagoonの新機能として取り込まれたようです。直接的なトリガーなのか、たまたまだったかはわかりません。最後にそのことについても触れます。
当日のイベントの様子は以下のソラコムさんのイベントページにまとまっています。
最初に当時のLTの内容について紹介します。
非接触温度センサーの可視化
LTではSORACOM Lagoonで非接触温度センサーの可視化についてお話をしました。このブログでも何度か紹介したPanasonicのGrid-Eye(AMG8833)は8x8の解像度をもつ非接触の温度センサーです。詳細は以下の過去記事を参照してください。
温度センサアレイを利用すると空間の温度分布を2次元データとして取得することができます。下手なところではエアコンの温度センサーや人発見に利用されたりします。それ以外にも機械の遠隔監視(異常温度の検知)などできるかもしれません。2次元のデータなので、温度の数値データを表示するだけでは人が直感的にわからないため、2次元のヒートマップ画像として表示することが直感的です。これをSORACOM Lagoonで表示させる方法について記載します。
SORACOM Lagoonで2次元ヒートマップを表示させるアーキテクチャ
SORACOM Lagoonのヒートマップパネルは時系列で、1次元のデータ分布の変化を表示させるヒートマップです。そのままでは2次元分布のヒートマップを表示させることができません。そこで、あらかじめ2次元ヒートマップを作成しておきます。その画像をDynamic Image Panelで表示させる方法をとりました。具体的には以下のように組みました。

Wio LTEを使い、AGM8833のデータを読み取ります。読み込んだデータはUnified EndpointからFunnel->GCP Cloud PubSubを通り、Cloud Functionに送られます。Cloud Functionでは送られてきたデータを2次元のヒートマップに変換して、特定のファイル名でCloud Storageへ保存します。また、UnifiedEndpointに送られたデータはHarvestへも送信されています。Harvestでデータを受けることでDynamic Image Panelのデータ取得のトリガーにします。
Dynamic Image Panelの設定
Dynamic Image Panelの設定では画像のURLにCloud Storageに保存さているファイルのURLを指定します。あらかじめ、Cloud Storageの設定を外部からHTTPリクエストでアクセスできるように設定しておきます。このままだとDynamic Image Panelがリクエストをキャッシュするため、アクセスごとに画像を読み込むためには「タイムスタンプを追加する」にチェックを入れ、URL末尾にタイムスタンプのGETパラメータを追加します。Cloud Storage側はGETパラメータを無視しますが、クライアント側からは別URLとしてアクセスするのでリクエスト時にキャッシュを利用しません。こうすることで、新しいデータが到達するたびに更新された画像を表示させることができます。

Dynamic Image Panelに表示される画像は以下の画像です。実際は8x8の画像ですが、Bicubic法で擬似的に解像度を上げています。

ちなみにカラースケールで値を表示させる方法は以前Qiitaに書いた以下の記事の方法を利用しています。
※余談ですが、最近この記事にが書籍で紹介さているようです。こうやって書いた記事が誰かの役に立つのは本当に嬉しい限りです。

- 作者: 下島健彦
- 出版社/メーカー: リックテレコム
- 発売日: 2019/11/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る

IoT開発スタートブック ── ESP32でクラウドにつなげる電子工作をはじめよう!
- 作者: 下島健彦
- 出版社/メーカー: 技術評論社
- 発売日: 2019/08/13
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
その後のお話
今回紹介した内容を当日のLTでお話しました。その中で課題として
「Dynamic Image Panel はパブリックに公開されているURLにしかアクセスできないので認証機能が欲しい」
という点を「ソラコムサンタ案件」として紹介しました。こういった機能がつけばプライベートな環境で逐次生成した画像の表示やカメラで撮影した画像の表示が安全にできるようになり、SORACOM Lagoonの活用の幅が広がると考えました。
そして時は流れてその半年後の10月、、、、ソラコムさんより以下のアナウンスが出ています。
今日の日経xTECH EXPO2019 特別公演で玉川より4つの新発表が!「SORACOM Harvest FilesとSORACOM Lagoon連携」「SORACOM Napter監査ログ機能」「VPGアウトバウンドルーティングフィルター」「SORACOM IoT SIM通信経路の最適化」です。もちろん今日からお使いいただけます! https://t.co/1dQqv5CBh1
— 松下享平 (Max@SORACOM) (@ma2shita) 2019年10月9日
なんとDynamic Image Panelの認証機能が発表されていたのです。まさにLTしたらSORACOM Lagoonがパワーアップしました!
まとめ
最初に書いた通り、本当にLTが要望トリガーになったかは定かではありません。おそらく他にも同様のリクエストがあったと思います。ですが、LTや事例発表のついでに自分の困りごとや提案を一緒に混ぜ込んでおくと目に止まりやすくなるはずです。こういうサービサーとユーザとのコミュニケーションができるのもソラコムサービスの魅力の一つだなと改めて感じた出来事でした。ソラコムサービスを利用されている方は困ってることやこういう機能欲しいを積極的に発信していくことをお勧めします。SORACOM UG Tokyoでは2020年2月にUGイベントを企画中です。もしLTや発表やってみたいよって方は#soracom_ugをつけてTwitterに呟いてみてください!また#ソラコムサンタでもリクエストを受け付けているようです。
今年も多くの要望が叶えられるであろうソラコムサンタを楽しみに待ちたいと思います。
AI RC Carをサマライズしたペーパーを作成しました。
この記事について
この記事はAI RC Car Adventcalendar 2019の最初の記事です。初日の今日はAI RC Carの紹介も兼ねて、AI RC Carの概要をまとめたポスターを作成したので公開します。
AI RC Carを紹介する資料
作成したポスターはタイトルが「DIY Self-Driving Car」になっていますが、AI RC Carとほぼ同じ意味で使っています。このポスターは改変をしなければ印刷、配布や転載は自由に利用して大丈夫です。ただ、何かに利用した場合はご連絡いただけると作者が泣いて喜びます(マストではありません)。商用についてはご相談ください。また誤字や修正点などあればご連絡ください。

紹介ポスターを眺めながらAI RC Carを理解する。
せっかくなのでこのポスターを眺めながらAI RC Carの概要をなんとなく掴んでいきましょう。それぞれのセクションごとの補足説明を書いていきます。
1. DIY Self-Driving Carとは?
AI RC Carを簡単に言うとディープラーニングを利用してコースを走行する移動ロボットの総称です。カメラで撮影した画像を頼りに、ステアリングとアクセルを調整しながらコースを進んでいきます。DonkeyCarやJetRacer, JetBotといった有名なものもあれば、オリジナルで作製されたAI RC Carもあります。
2. ハードウェアの基本構成
AI RC Carのハードウェア構成はいたってシンプルです。コースを撮影するためのカメラとディープラーニングを推論して制御を行うシングルボードコンピュータ、それにモータドライバが必要です。これらをラジコンの車体やロボット台車へ搭載すれば最低限の機能を満たします。カメラについてはFPV 160°と広角のカメラが用いられることが多いです。また、シングルボードコンピュータはJetson NanoやRaspberry Pi 3B+を利用します。Jetson Nanoではディープラーニングの学習もJetson Nano上で実行できます。モータは基本的に2つのみです。ラジコン車体ではステアリング用とアクセル用に利用します。対向二輪型のロボット台車では左右両輪を独立したモータで制御します。
3. ディープラーニングを使った走行の仕組み
ディープラーニングの使い方には大きく二つの方法があります。一つはディープラーニングが画像を入力としてモータの制御値を直接出力する「End-to-End方式」です。もう一つは画像から、進行方向をX,Yの画像上での座標値として出力する方法です。ここでは「ハイブリッド方式」と呼びます。前者はDonkeyCarでよく使われるオーソドックスな方式です。出力が車体のパラメータと密接に関係するので車体ごとに学習が必要です。後者はJetRacerやJetBotのサンプルコードで利用されています。車体ごとのパラメータは後段の制御器で吸収するため車体ごとの学習の必要がありません。しかし、制御パラメータの微調整が必要になります。
それぞれの方式で使われるディープラーニングのネットワークの構造は実は同じネットワークで実現できます。また学習方法もMSE Lossを目的関数に置いて、回帰問題として学習させることができます。違いは学習データの与え方です。「End-to-End方式」では人があらかじめ運転する教示走行時の画像とラジコンプロポからの入力値を教師データとして学習します。「ハイブリッド方式」では進行方向を画像上での座標を教師データとして学習します。
「End-to-End方式」ではディープラーニングのネットワークは3層のCNNを用いて実現されることが多いようです。この場合、未学習のネットワークを学習させるため、数千枚の画像をサンプリングし学習を行います。学習にはGoogle Corabolatoryなどクラウドのサービスを利用される場合が多いようです。Donkey Carで利用されるモデルは以下のリポジトリから確認できます。KerasLineaがよく利用されます。
「ハイブリッド方式」では人手でのアノテーションが必要になります。そのため、多くの画像をサンプリングすることが難しいです。そこで転移学習を利用した学習を利用します。ResNet-18などの軽量の物体認識モデルをベースに転移学習します。学習データ数はコースなどにより変化しますが、単純な周回コースであれば50から100枚程度の画像で十分に学習できます。JetsonNanoであれば10分程度と現実的な時間で学習が完了します。
日本のコミュニティについて
より AI RC Carを深く知るには実際に動いているAI RC Carを見て、自分で手を動かすことが重要です。そのための日本での情報源、コミュニティについて紹介します。
Facebookグループ
AI RC Carに関連するFacebookグループはいくつかありますが、個人的な主観で一番活発に思えるのが「AIでRCカーを走らせよう!」グループです。このページでは活発な意見交換ややってみた記事、走行会情報が流れてきます。
Slack グループ
上記Facebookグループから派生してSlackのコミュニティ AI Car Communityがあります。世界的なSlackのグループとしてはDonkeyです。こちらはDonkeyCarのコミュニティーページから参加することができます。英語でのコミュニケーションですが、海外での盛り上がりを感じることができます。申請すればどなたでも参加することができます。
まとめ
2018年末ごろから徐々に盛り上がりを見せたAI RC Carですが、2019年はより大きな盛り上がりを見せた年だったのではないでしょうか。私自身、今年の春ごろからなんとなく存在を知り、7月にはどっぷりと沼にはまっていってしまいました。初めて見ると意外に簡単に始めることができます。その後奥の深さにどっぷりとひきづりこまれますが。。。もう始めているよという方も、この記事を見て興味を持ったという方も、2020年はどこかで一緒にAI RC Carを走らせられることを楽しみにしています。
AI+IoTなデバイスをお手軽に作れるM5StickVとSORACOM LTE-M Button Plus
1. この記事について
夏の終わりに身の回りのものを整理していたら、購入していたまま放置していたM5StickVとSORCOM LTE-M Button Plusを発掘した。こんな二つを悪魔合体することでお手軽にAIとIoTを組み合わせられるのではと思いつき、「ソラコムポーズを取るだけで触れることなくSORACOM LTE-M Button Plusnを押す」を試してみた。
果てしなき鍛錬の果に、手でソラコムポーズを取るだけで、SORACOMボタンに触れることなくクリックできる異能の力を身に着けてしまった。。。#soracom #soracomug #高度に発達したSORACOMは魔法と見分けがつかない。 pic.twitter.com/L09lO5T7Fy
— masato_ka (@masato_ka) August 31, 2019
念の為説明しておくと映像の左上にはM5StickVで撮影した映像が写っている。この部分にソラコムポーズをした手が映るとM5StickVがソラコムポーズを認識してLEDの色を変える。その後三秒ほど待つとM5StickVがリレーを動かしてSORACOM LTE-M Button Plusを動作させる。
補足 ソラコムポーズとは
ソラコムポーズは右手と左手を組み合わせて「S」の字を作ることをそう呼んでいる。株式会社ソラコムサービスを利用しているユーザが集まって構成されているSORACOM UGではユーザグループイベント終了時に希望者でこのソラコムポーズを撮り集合写真を取ることが慣例となっている。
そんなSORACOM LTE-M Button Plusと縁もゆかりも深いソラコムポーズをキーとしてボタンを押すことができるようになる!
2. やったこと
こんな素敵な使い方ができるデバイス実現のポイントについて解説する。
2.1. M5StickVとSORACOM LTE-M Button Plusの接続
実現したいことはM5StickVとSORACOM LTE-M Buttonを繋げることだ。SORACOM LTE-M Button Plus にはボタンの代わりにA接点が搭載さ入れてる。 M5StickVでソラコムポーズを認識した後、Groveリレーモジュール を介してSORACOM LTE-M Button PlusをA接点をONにする。これでAIの推論結果に応じてSORACOM LTE-M Button Plus経由で情報をクラウドへ上げることができる。立派なAIoTなデバイスの完成だ。接続は無極性の接点接続とGrove端子の接続のみなので難しいことはない、フォースの感じるままに接続すれば良い。

2.2. M5StickVのモデル学習
ソラコムポーズを認識させるためにはそのための学習データが必要となる。今回は200毎程度のソラコムポーズを取った手の画像とソラコムポーズを取っていない手の画像を同じく200毎程度作成し学習のデータセットとした。画像サイズは244x244だ。
学習モデルはImageNetでpre-train済みのモデルから転移学習を行なっている。学習はGoogle Colaboratoryで行なった。Google Colaboratoryで動かすPython notebookは以下を参考にさせてもらった。
https://colab.research.google.com/drive/1mirG8BSoB3k87mh-qyY3-8-ZXj0XB6h6
上記のノートブックでは転移学習の際に、MobileNetの畳み込み層の重みは変更しない設定となっていた。何度か学習を試みたが精度が芳しくなかった。そこで、過去の経験からMobileNetの畳み込み層の最終レイヤのみ重みを学習するように変更を行なった。はっきりとはわからないが、pre-train済みのモデルは画像から十分に特徴を抽出できる性能を持っているが、最終段のみタスクに合わせて微調整すると良いのではないかと思っている。(学術的な裏ずけは何もないおまじないです)
上記、Python notebookの「Transfer learning using MobileNet V1」節、2つ目のコードブロックを以下のように変更した。
# 変更前 for i, layer in enumerate(base_model.layers): layer.trainable = False
# 変更後 for i, layer in enumerate(base_model.layers): layer.trainable = False if i > 80: layer.trainable = True
Python notebookを最後まで実行するとモデルとモデルを動かすためのMicroPythonのスクリプトがzipファイルとしてダウンロードされる。
ちなみにデータさえあれば細かいことは気にせずAI作れる専用のサービスも始まったようです。
M5Stack - A series of modular stackable development devices
2.3. M5StickVへのモデルの書き込み
作成されたモデルはM5StickVに配置してプログラム上からロードして利用する。モデルはMicroPythonで書かれたソースコードとともにSDカードに書き込んで、M5StickVにSDカードごと差し込んで利用する使い方が主流だ。M5StickVのファームウェアはSDカードにboot.pyファイルが入っているとそちらを優先して起動するようになっている。しかしM5StickVのSDカードは相性問題がシビアなため、今回はモデルとプログラムを内蔵Flash ROMへ書き込んで利用した。ソースコード中でモデルをロードしている箇所ではFlash ROMのモデルが書き込まれているメモリ番地の先頭をload関数に渡すことでFlash ROMに書き込んだモデルを読み込むことができる。書き込みやモデルロードソースコードのイメージは以下のサイトがわかりやすい。
下記サイトからmaixpy_v0.4.0_39_g083e0cc_m5stickv.binをダウンロードし、FlashROMの先頭0x000000へ書き込む。モデルは0x300000あたりを先頭にして同時に書き込みを行う。
Index of /MAIX/MaixPy/release/master/maixpy_v0.4.0_39_g083e0cc/
3. M5StickVとSORACOM LTE-M Button Plusを組み合わせると何がいいのか。(まとめ)
M5StickVはカメラとディープラーニング向けアクセラレータが搭載されたRISC-V CPUK210が搭載されたデバイスだ。内蔵のリポバッテリーでディープラーニングを利用した物体認識や物体検知を動かせることができる。しかし、現状のバージョンでは外部との通信機能はついていないため、認識した結果をクラウドに送るなどIoTや遠隔センシング用途に使うには工夫が必要になる。
対して、SORACOM LTE-M Button Plusは低電力のLTE-M通信ができるデバイスだ。その基本機能は3パターンのボタンクリック(シングルクリック・ダブルクリック・長押し)をイベントとしてクラウドへ通知することだ。また簡易位置計測機能がついているため、通信時の基地局情報を元に位置情報と合わせて送信することができる。つまりこの2つを悪魔合体して得られる効果は以下のようになる。
- 必要に応じてディープラーニングのモデルを差し替えるだけで、汎用的なセンサとしてM5StickVを利用することができる。
- 認識した結果に応じて簡易位置計測による位置情報とともにイベントをクラウドに送ることができる。
- M5StickVもSORACOM LTE-M Button Plusもそれぞれバッテリー内蔵なのでポータブル性に優れている。
これこれ、こういうのでいいんだよ、最高じゃないか!例えばM5StickVで鳥獣か人かを認識してSORACOM LTE-M Button Plusで位置情報をともにクラウドプラットフォームに送ることで監視アプリができる。田畑をカメラで見張れば正確な水位はわからなくても水位が多い少ないくらいは非接触で見分けることができるだろう。部屋の中でのジェスチャー操作で照明を制御するというのも面白そうだ。M5StickVとSORACOM LTE-M Button Plusの愛称は抜群かもしれない。
AI+IoTでお手軽に何か作ってみたいと思ったら選択肢の一つとして強くオススメしたい。
JetsonにEdge TPUにM5StickV で、エッジAI用やるには何を選べばいいの?
1. 概要
追記 公開当初Jetson Nanoの性能表記に誤記があったため修正しています。
最近組み込みデバイス(以下エッジと表現)で画像認識や音声認識、センサ情報の処理といったディープラーニングを利用した処理を実行することが容易になっている。低消費電力で、高速にディープラーニングを処理するためのエッジAI用アクセラレータが各社から発売されていることがその理由の一つだろう。
こういった、エッジAI用のアクセラレータは各社によってその使用や対応フレームワーク、利用できるディープラーニングのネットワーク構成に違いがある。どれも同じように利用できるわけではない。自分でエッジAI用アクセラレータを利用しようとしたときにいくつか調べてみた内容をメモがわりに残してみる。ちなみに個人で遊べるものを中心にしてるので、産業的にどうなのかは知らない、悪しからず。。。 あとこのブログではAndroid Thingsとかいう「実績」があるので話半分で読んでいただけるとありがたい。

2. 比較対象のエッジAIアクセラレータについて
比較する対象は以下のボードである。現在個人でも入手が容易で利用時の取り回しが良さそうなものを恣意的にピックアップした。名称の粒度もボードだったりチップだたりまちまちだけど自分の呼びやすさで書いている。(免責事項)
今回はFPGAについてはちょっと毛色が違うので扱わない事にした。またSpressensなどについては後述するがAIアクセラレータは入っていないと判断した。(もし専用の処理回路が入っていれば指摘してほし。) それぞれについて簡単に紹介しておく。
2.1 Coral Edge-TPU(USB/Board)
Googleのディープラーニング用アクセラレータであるTPUのエッジ版となる。USB3.1接続のドングルとCoral Dev Boardと呼ばれるRaspberry Piライクなシングルボードコンピュータが存在する。USB接続の場合は3.1接続以外でも利用できるが処理速度が多少落ちるという話もある。
- 参考
Edge TPU USB Acceleratorの解析 - Operationとモデル構造 - Qiita
2.2 Neural Compute Stick 2
Intel社が出している、 Myrad X VPUを搭載したUSB接続タイプのアクセラレータだ。後述するがTensorFlowやCaffeなどのフレームワークに対応し、IntelのOpenVINOという開発環境で開発することができる。以後NCS2と呼ぶ。
2.3 K210
中国のKendryte社のRISC-Vプロセッサである。KPUというディープラーニング用のアクセラレーション機能が入ってる。最近流行りのM5StickVやSipeed Maixシリーズに搭載されている。
2.4 Jetson Nano
Jetson Nano はNVIDIAのTegra X1(Nintendo Switchの中身らしい)で作られたシングルボードコンピュータだ。GPUなのでAIアクセラレータかというと疑問はあるが、用途としては組み込みでのAI処理がメインだと思うのであえてリストに載せている。
3. エッジAIアクセラレータの比較
前出のアクセラレータをそれぞれ比較してみる。軸もかなり恣意的だが以下のようなった。しつこいが、Jetson Nanoは基本的にGPUだ。
- 2019/8/30 コメント欄記載の通り、Jetson Nanoの処理能力を誤記していたため修正
| アクセラレータ | Edge-TPU | Neural Compute Stick 2 | K210 | Jetson Nano |
|---|---|---|---|---|
| 処理能力 | 4TOPS | 4 TOPS(NN用に1TOPS) | 0.25TOPS〜0.5TOPS | 472 GFLOPs(FP16) |
| 浮動小数点計算 | - | FP16 | - | FP16,FP32 |
| 消費電力 | 0.5w(1TOPS) | 不明 | 0.3w(0.25TOPS) | 5w~10w |
| 開発ツール | Edge TPUコンパイラ,Python/C++ API | OpenVINO | MaixPy(MicroPython) Kモデル用変換ツール | CUDAライブラリ |
| 対応フレームワーク | TensorFlow Lite | Tensor Flow, Caffe, MxNet, Kaldi | TensorFlow Lite, Darknet | TensorFlow Lite, Keras| TensorFlow, Keras, TensorRT, Pytorch |
| クラウドサービス | GCP AutoML Vison Edge | - | M5StickVのβサービスあり | - |
| 対応モデル(掲載以外も対応あり) | InceptionV3, SSD-MobileNetV2(300x300), PoseNet | ResNet, SSD-MobileNetV2(300x300), Tiny-YOLOv3, OpenPOSE,UNET | Tiny-YOLOv3, MobileNet | 特に制限なし |
| on device学習の可否 | 物体認識の限定的な転移学習のみ | 不可 | 不可 | 可能 |
| 備考 | 上記値はおそらくUSBドングルバージョンの値 |
- 参考
第 1 回 Jetson ユーザー勉強会 K210 introduction Google Coral Edge TPU vs NVIDIA Jetson Nano: A quick deep dive into EdgeAI performance https://www.taxan.co.jp/jp/pdf/products/topics/ncs2_brochure.pdf Hardware For Every Situation | NVIDIA Developer
それぞれの項目について以下補足していく。
3.1 処理能力と浮動小数点演算
処理速度ではTOPS(Tera | Tensor Operations per sec )を基準値とした。ただあくまで指標レベルに考えておいたほうがいいかもしれない。後述するが、同じモデル動かすにもアクセラレータによってモデルのどの処理をサポートするか変わるようだ。また実装によっても速度が変わるだろう。Edge TPU、NCS2、K210と続いており、おおよそ感覚的にもこんな感じなんではないだろうか。(2019/08/30 コメント欄記載の通りJetson Nanoについては472GFLOPs(FP16)となる。)
通常ディープラーニングは浮動小数点の演算を行うが、量子化といって、計算速度を上げるため、推論精度をある程度落とし8bit整数などで演算できるようモデルを変換して利用する。そのため、それぞれの値は別途記載がない限り整数演算の能力となる。ただし、NCS2とJetson Nanoは浮動小数点演算をサポートしている点も付け加えておく。
3.2 消費電力
Edge TPUは1TOPSあたり0.5Wとのことなので、フルで使うと2W程度になるはずだ。対して、K210は0.3TOPSで0.25Wなので、実際の消費電力としては少ないが、効率としてはEdge TPUが良さそう。Jetson Nanoについてはそれでも5W程度で動くのだから効率は結構いいともう。ちなみにNCSの消費電力については公式情報がなかったため割愛する。デバイス単体の電力で見るとK210が小さい。
3.3 開発ツール
エッジAI用アクセラレータを使うためには以下の3種類のツールが必要になってくる。
ディープラーニング用フレームワーク
ディープラーニング用のフレームワークはエッジAIのモデルそのものを作るためのフレームワークだ。今回のデバイスでは全て共通してTensor Flow, Keras利用することができる。またNCS2ではCaffeフレームワークを使うことができる。Jetson NanoについてはUbuntuが動いているので環境を構築すればなんでも動かせるだろう。ちなみにサンプルではPytorchの例が多いようだ。
ONNXなどでフレームワーク間でモデルを変換してということもできるかもしれないが、ONNX自体各フレームワークでの対応状況がまちまちなようなので、後述のモデル変換の話を考えるとどのフレームワークも制限なく使えるという訳ではないようだ。利用前に、事前の検証が必要そうだ。
モデル変換ツール
Jetson Nano以外のエッジAIアクセラレータを利用するためには各アクセラレータに合わせてAIのモデルを変換する必要がある。そのためのツールがモデル変換ツールだ。モデル変換のツールについてはもちろん各アクセラレータごとに用意されている。注意したいのは各アクセラレータごとに、サポートしている処理が違う点だ。ここでいう処理とは畳み込み層やプーリング層、ReLu関数、全結合層、Softmax関数といったデープラーニングのフレームワークでネットワーク記述する際に用いられる各関数のことを指す。乱暴にいうとこの対応処理に違いがあるため、アクセラレータごとに実行できるディープラーニングのモデルが変わってくる。CNN以外は割と難しいのではないだろうか。
例えばEdge TPUの場合は、Tensor Flowで作成したモデルを量子化した上でTensor Flow Lite(tflite)モデルに変換し、Edge TPUのモデルへモデル変換ツールを利用して変換を行う。ニューラルネットワークの入力層から変換を行っていき、変換中にEdge TPU でサポートしていない処理が現れた場合は移行の処理はCPUへフォールバックするようだ。
このような場合に、NCS2で利用されるOpenVINOやK210の変換ツールがどうのような挙動をするかまだ調査がついていないが、おそらくEdge TPUと同様か、そのまま変換できないかのどちらかだろう。 また、生成されるモデルのサイズによってはメモリに乗らないなどの問題モデルだろう。この辺りは各アクセラレータの資料をみるのがいいだろう。下記のInterface 2019年8月号に記載されているEdge TPUの解説記事ではEdge TPUの性能を出すための条件が書かれている。このように各アクセラレータごとの癖があると思う。決して万能ではない。
 2019年 08 月号")
Interface(インターフェース) 2019年 08 月号
- 出版社/メーカー: CQ出版
- 発売日: 2019/06/25
- メディア: 雑誌
- この商品を含むブログを見る
- 参考
TensorFlow models on the Edge TPU | Coral Release Notes for Intel® Distribution of OpenVINO™ toolkit 2019 | Intel® Software Optimization Guide - OpenVINO Toolkit
推論用API
モデル変換後は実際にデバイスへモデルをデプロイして推論処理を行う。この時に各デバイスへモデルをロードして推論させる必要がある。Edge TPUは専用のPython/C++ APIが提供されている。NCSではOpenVINOのPython APIを利用できる。K210はMaixPyというMicroPython環境でAPIが提供されている。Jetson Nanoは各フレームワークの推論APIを利用することになる。それぞれのAPIは透過的に各デバイスの制御を行っている。
ちなみにUSB版のEdge TPUとNCS2は複数本接続することにより、並列で推論させることが可能なようだ。やり方についは以下の記事で@PINTOさんの貴重な記録を確認することができる。
各アクセラレータの対応モデルについてはモデルの実装方法と変化ツールの対応状況がキーとなるので、利用したい/実装したいモデルと変換ツールの対応状況を合わせて確認する必要があるだろう。
3.4 AIモデル作成のクラウドサービス
AIモデルを開発するためには基本的に前述の開発ツールが必要になる。が、Edge TPUについてはGCPのCloud AutoML Vision Edgeというサービスを使い、クラウドサービスに学習用データをアップロードするだけで、Edge TPU対応もデールを自動的に学習、生成させることができる。ただし、物体認識のモデルのみが対象となる。また、K210についてもデータをアップロードするだけでKPU用モデルが出力されるV-TrainingというサービスをM5StickV向けにベータ提供していた。今後、正式版が出るかもしれない。
基本的には転移学習により学習済みでると少量データで学習させるのだが、自前でやるとハイパーパラメータの調整や、学習スクリプトを毎度用意するのがめんどくさいので、こういうサービスを利用できるのはアドバンテージになる。
3.5 On device 学習
これまでの話は基本的にエッジ側で推論を実行するための話だ。しかしエッジ側で学習させたいユースケースもあるだろう。こういった要望に答えられるのはJetson Nanoしかない。ここが低消費電力で動くパワフルなGPUの醍醐味だと感じる。
エッジAIアクセラレータとしてはEdge TPUがMovileNet v1用の学習が行える。学習といっても最終段の全結合層のみをCPUで学習させて使えるようにするだけなんじゃないかと思う。試した訳ではないが、簡単な画像分類だったらできそう。
Retrain a classification model on-device with backpropagation | Coral
Retrain a classification model on-device with weight imprinting | Coral
4. その他番外編
エッジAIでは必ずしもアクセラレータを必要とする訳ではない。処理速度を問わなければRaspberryPi 3B+を使うというのも手かもしれない。また、IdeinのActcastを使うとRaspberry Pi Zeroでの30FPS以上で物体認識やPoseNetを動かすことができる。また、SonyのSpressenseもディープラーニングモデルを実行することができる。こちらはSonyのクラウドサービス、Neural Network Consoleで生成したモデルをSpressense用に変換することで利用することができる。
今回は取り上げなかったがTensor Flow Lite for microcontrollerといった、ARM M0 CPUで動かせるモデルをC++のコードとして生成するフレームワークもある。
5. まとめ
で、エッジAIやるには何を選べばいいのか?個人的にはとにかく、組み込みでAIっぽいことしてみたいと思ったらJetson Nanoで遊んでみるのが一番いいんじゃないかと思っている。一番制約なくパワフルに使えるからだ。その分消費電力も大きい。価格は1万2千円程度とコストパフォーマンスは良い。
物体検出や認識を動かしたいのであればEdge TPUのUSB版もいいだろう。ただしUSB 3.1で真価をはっきするようなのでRaspberry Pi3B+がホストだと辛い。Jetson Nanoに挿してもいいだろう。Coral Dev Boardを使ってみるのもいいかもしれない。価格はUSBドングルで1万円、Dev Boardで1万8千円するのでJetson Nanoに比べると割高感はあるかもしれない。ただUSBアクセラレータの場合は好きなシングルボードコンピュータをAI対応できる魅力がある。
NCS2は対応モデルやフレームワークの数で言えばEdge TPUより優れているだろう。またIntel のOpenVINOも強力なツールなので、USBドングル式のアクセラレータの選択肢に入れて良いだろう。
バッテリーで動くお手頃サイズのデバイスを作りたければ K210を搭載したM5StickVやSipeedのボードを買うのが良いのではないだろうか3000円程度からデバイスが手に入っる。もちろん、Spressensを買うのもありだろう。
どんなモデルを使いたいのか、つまりアクセラレータと変換ツールの対応状況を検討し、動作させるシュチュエーションや電力などのリソース、価格に注意して選択するのが良いと思う。
ディープラーニングとJetson nanoでEnd-to-Endな自動走行を実現した話〜Jetpilotを作ってみた〜
1. この記事について
Jetson nanoを搭載した移動ロボットJetbotを作成し、前回はJetbotを使った単眼vSLAMを実行させた。
しかしvSLAMはPC側で処理される。Jetson nanoはPCへ映像を送信するだけだ。これでは搭載されているGPUが活躍していない。せっかくなのでJetson nanoに搭載されているGPUの威力を体感したかった。
そこで今回はディープラーニング を利用して画像から直接判断して走行する、End-to-Endな自動走行にチャレンジしてみた。コースを追従するだけであれば、単純な画像認識によるライントレースと簡単なルールベースの仕組みで十分だろう。しかし、今回は前提となるルールを作るのではなくデータだけ与えて、ディープラーニングで解くのがポイントとなる。以下の画像のようにJetbotがコース上を追従して走行していくイメージだ。

2. End-to-Endのディープラーニングによるラジコン自動走行の方式
End-to-Endの自動走行について説明する。ここでいうEnd-to-Endの自動走行とは以下のNVIDIAの論文のように車両で撮影した画像から直接その車両を制御する信号をディープラーニングで推論することを目指している。以下、論文の例では走行中の画像を撮影して、道路の状況に即して最適なハンドル操作角、つまりステアリング制御を行なっている。
実車を公道など複雑な環境で自動走行する場合、SLAMなど自己位置推定の技術に加えて、ディープラーニングを利用して障害物や標識を探し、走行ルールに則り車を制御するのが一般的かもしれない。そのためEnd-to-Endな使い方は知る限り実車では例が少ない。しかし、近年草の根の盛り上がりがあるDIY Robot CarやAI RC Carと呼ばれる分野でいくつもの先例がみられる。
2.1 Jetbotのroad_followingサンプル
Jetbotのサンプルリポジトリにはroad_followingというサンプルがある。これは自動走行したいコースの各ポイントで画像を撮影する。撮影した画像のそれぞれで、進行方向となる点をマーキングしその画像上でのX,Y座標をラベルとする。この学習データを元に転移学習されたResNetはコース走行時に、画像場で推定された進行方向の座標(X,Y)を返す。この座標を目標にPID制御でJetbotを動かすと言うものだ。上位ランクのJetRacerも基本的には同じ仕組みになっている。
https://github.com/NVIDIA-AI-IOT/jetbot/tree/master/notebooks/road_following
画像上での進行方向を推論し、その進行方向を目標値としてPID制御によって車両を制御している。正確にはEnd-to-Endにはなっていないが、実現方式としては近い。
2.2 DonkeyCar
ラジコンカーにRaspberryPiまたはJetson nanoをマウントして作成するDonkeyCarでは人間の操作を直接学習さる。手順としては以下の通りだ。
- ラジコン操作で人間が実際に教示走行させる
- 教示走行で走行画像と合わせてそのタイミングで人間が操作した速度とステアリングの値をラベルとして記録する。
- 学習データを元に入力画像に対して最適な速度とステアリングを学習する。
DonkeyCarではいくつかのDNNのネットワークモデルが提供されている。上記のNVIDIAの論文に記載している素朴なCNNを使い、分類問題として解く方法や、回帰問題として学習させる方法がある。また、3D-CNNやRNN, LSTMを利用し、前後の画像列から時系列での動作を意識したモデルを学習をさせることもできる。DonkeyCarにどんなモデルが実装されているかは以下のリポジトリからKerasでの実装を確認できる。
donkeycar/keras.py at dev · autorope/donkeycar · GitHub
学習は1万枚程度の画像を使い素のネットワークから学習する。1万枚と聞くとかなりの量に感じるが、コースを10周もすれば集まるようだ。 DonkeyCarでは画像から車両の制御情報を直接推論するため、End-to-Endな方式と呼んで問題ないだろう。
2.3 今回実装した方法
road_followingのデモでは画像一枚ごとに自分で画像上でマーキングを行いラベルをつける必要がある。また、End-to-EndではなくPID制御がシステムに入っている。DonkeyCarは教示走行により学習データを集めるため、比較的に簡単にデータを収集できる。また、End-to-Endの学習を実現している。しかし、DonkeyCarではネットワークをゼロから学習するため、Jetson nano上で学習するのに時間がかかる。 そこで今回はroad_followingで使用されている転移学習のコードをベースにDonkeyCar同様、画像とコントローラからの指令値をペアにした学習データを与えて学習させる方法をとった。
3. 実装
ソフトウェアの実装ではROSを使ったコードで試作し実現性を確認した。その後、公開、利用がしやすいようにJupyter notebookとして再実装した。このnotebookは3つのノートブックで構成されている。学習データの収集にはUSB接続のゲームコントローラを必要とする。詳細な利用方法や実装については以下リポジトリを掲載する。プロジェクト名はJetpilot名付けた。
以下、実装時のポイントについて解説していく。
3.1 学習データの取得 (data_collection.ipynb)
学習データの収集はコースをJetbotをゲームコントローラで走行させる。コースはテープなど2本のラインで構成された1週可能なものを想定しいてる。走行時に画像と一緒にコントローラの入力値を画像のファイル名として[speed]_[steering]_[uuid].jpgという形で保存していく。画像の保存はカメラの画像取得タイミングと同期しているため、カメラのFPSを10Hzに設定するとサンプリングの間隔は10Hzになる。ただ正確に計測していないので10Hzは厳密ではない。以下映像のようなコースの場合、3〜5周ほど周回ささせ700〜900枚程度になる。
※ 音が出るので再生には注意
Jetbotとディープラーニングで自動走行を学習させる
Jetbotのサンプルはtraitletsというライブラリとipywidgetを使ってJupyter notebook上でインタラクティブなアプリを実装している。今回もこれらを利用してゲームコントローラの入力処理や画像の取得処理、Jetbotの制御を行なっている。 Jetbotの運動制御はmobile.pyのMobileControllerクラスで実装している。このクラスにSpeedとSteeringの値を入力することでJetbotを制御できる。Jetbotは単純な対向二輪型のロボットのため、制御に使う逆運動学は既知の式を利用している。
車輪ロボット(対向2輪型)の運動を計算してみよう | Tajima Robotics
Speedについては入力値をある範囲で区切り、離散化している。Steeringの値は60cmを最大値とする旋回半径として与えられ、与えられた値が大きくなるにつれ、旋回半径が短くなるようにしている。つまり、コントローラを大きく倒すほどJetbotが急激に曲がることになる。
3.2 学習(train_data.ipynb)
学習スクリプトはroad_followingのサンプルをベースにResNet18をベースに転移学習を行った。出力はtorch.nn.Linear(512,2)としてSpeed とSteeringの値を出すようにする。MSE-Lossを使用して回帰問題として学習させる。
road_followingの学習スクリプトから大きな変更はない。road_followingでは画像上でのXY座標を回帰問題として求めるのに対して今回はその時のコントローラの出力値を出力するだけだ。違うのは与えるデータだけ。そのため、Datasetクラスの実装で画像名からのラベルデータの取り出し部分を変更している。
ResNet18のLayer1からLayer3までは学習しないようにフリーズすると少ないエポック数でそれっぽく学習できた。ResNetの畳み込み層はLayer4までなので最後の特徴抽出層とその後の全結合層のみ学習させる。次のコードで層をフリーズさせることができる。
# ResNet18のLayer1からLayer3までを学習しないようフリーズさせる場合は、学習前に追加 for param in model.layer1.parameters(): param.requires_grad = False for param in model.layer2.parameters(): param.requires_grad = False for param in model.layer3.parameters(): param.requires_grad = False
それ以外にもvalidation lossが下がらない場合に過学習しないよう、学習を止めるEarlyStoppingを設定した。10〜30エポック程度で停止する。 Jetson nano上でそのまま学習させることもできるが、Google Coraboratoryなどで学習させると短時間に学習できる。
3.3 走行の様子(live_demo.ipynb)
学習したモデルを使い実際にJetbotを走行させる。各フレームで入力された画像からスピードとステアリングを直接推論する。推論された値はそのままSpeedとSteeringになるので前述のMobileControllerへ直接与えることで走行することができる。 走行中のフレームレートを稼ぎたいため、推論では半精度の浮動小数点で計算をしている。以下が、走行時の動画となる。
※ 音が出るので再生には注意
Jetbotとディープラーニングで自動走行を学習させる
見事コース一周に成功。しかし、数回走らせたうちの1回成功なので精度的にはまだまだ改良の余地がある。
3.4 Grad-CAMでの評価
実際に走行できたが、このモデルはなにを見てスピードとステアリングを決めているのか?Grad-CAMと呼ばれる手法を用いて、各画像の推論時に画像のどの部分が結果に一番寄与したのかを可視化した。今回はSteeringの推論にて画像中のどの部分が特徴として一番寄与したかを可視化している。動画中の色が赤に近づくほど結果への寄与が高いことになる。
基本的には白線部分をみているようだが、大きくカーブする場面では画像全体を均一に特徴として捉えている。過学習っぽいのかな。
4. やってみて学んだこと
以下、やってみて自分で感じたことなどを記載しておく。ごくごく当たり前の内容も含まれているが、自分でやってみると以外に見落としがちだった。
4.1 データ取得のための調整
そもそもディープラーニングで学習する前にデータ取得での地道な作業が重要だった。データ取得での調整ポイントは次の通りだ。
- コースのレーンの色がはっきりとわかるようにする。(コースとそれ以外のコントラスト)
- 速度が0のデータや誤操作時の画像の除去といった学習データのクレンジング
- 学習走行時に周回ごとに操作がなるべくブレないようにする。これもデータを綺麗にする意味で重要
- カメラの設置角を調整して画像内でのコースの割合を大きくするといったハードウェア周りの調整。
一般的にデータの前処理は地味だが重要な作業という。今回の場合も例外にもれず、身をもって体感した。また、ロボットなどハードウェアが絡む場合ではハードウェアの調整も重要なポイントとなる。
4.2 エッジ学習のやり方
Jetson nanoで試行錯誤しながら学習するには処理が遅い。そこで、同じコードでGoogle Coraboratoryなど他の環境で学習し、エポック数やデータセット、バッチサイズなどのハイパーパラメータを調整しておく。「あたり」をつけたパラメータを使いEdgeで学習させると効率的。そのため、エッジ側とクラウド側で同じ環境、同じコードで学習できることが重要。今回はJupyter notebookが役に立った。
こうなると全部クラウドでと考えてしまうが、データの収集、学習から推論まで エッジでできるのは手軽さがあり、データの転送など煩雑な操作がない分、手軽さがある。クラウド側とエッジ側の分担や使いわけはまだまだ課題だろう。
また、エッジのように利用するデータを少なくしなければならない場合は転移学習は強力な手法になる。ゼロから学習させると画像の枚数が多くなり、Jetson nanoでの学習は現実的に厳しい。Jetson nano上で学習させるなら転移学習させるのが現実解なのだろう。
4.4 過学習に気をつけろ
最初は何も考えず、 70エポックをフルで回していた。Early Stopping入れることで短い時間で割と良い結果が出ることに気がついた。エポックの回数をむやみに増やせば良いというものでもないのだな。
4.5 GPUメモリリーク
当初Jetson nano上で400枚程度の画像でGPUのメモリが足りなくなり、学習が止まってしまう問題があった。これはGPU上のメモリに保存されているLossの値をトータルLossの計算でそのまま加算していたため、トータルLossの値がGPUのメモリを確保し続け、メモリが足りなくなる事象が発生していた。 GPUはGPUに得意なことしかさせない。GPUを使わない処理や必要のないデータはGPUのメモリから外すようにするというのが特にエッジGPUでは重要だろう。
ちなみにこの修正は本家のリポジトリへプルリクエストを送ってみた。マージされるといいな。
Fix GPU memory leaks. by masato-ka · Pull Request #117 · NVIDIA-AI-IOT/jetbot · GitHub
5 まとめ
ディープラーニングを使ったEnd-to-Endな自動走行を実現した。ちゃんと教示走行を学習してそれっぽく動く姿は非常に興味深かった。今後はモデルを変えたり、センサ情報や、画像上に移った物体の情報で動きを変える(標識の画像で一時停止や反転など)ようなものに発展させたい。
お礼
この記事を執筆するにあたり、茅場町 コワーキングスペースCo-Edoの会議室を実験、撮影にて利用させていただきました。
JetbotでOpenVSLAMを試してみた。
この記事にてついて
この記事ではJetbotを使ってOpenVSLAMを動かした内容をまとめている。SLAMの実行はJetson nanoではなく、別のホストマシンで実行した。ROSの設定方法や、動かし方を中心に記載している。
ROSで使える単眼SLAM
ORB_SLAM2とOpenVSLAMがROSパッケージのサンプルを同梱している。ORB_SLAM2のROSサンプルはSLAMのローカライゼーション結果(カメラの姿勢)もトピックに投げられるようになっている。OpenVSLAMはローカライゼーション結果はビュアーに表示されるのみだ。またORB_SLAMとOpenVSLAMは実行結果の表示にPangolinと呼ばれるOpenGLを使った3DViewerライブラリを利用する。そのためそれなりのビデオチップを搭載したマシンが必要になる。OpenVSLAMではPangolinを使わずにWEBブラウザのみで描画可能な表示モードが用意されている。今回はこれが決め手となり、OpenVSLAMを利用することにした。ちなみにORB_SLAM2はGPLv3でOpenVSLAMはBSDでそれぞれ公開されている。
環境構築
構成
SLAMの実行はVirtualBox上のUbuntu 18.04で実行した。物理マシンはMacBook Air 2018 メモリ16GBを利用。ROSのマスターはJetbot側にある。Jetbotで取得した画像はimage_procで圧縮し、/jetbot/image_rawへパブリッシュされる。ホスト側のUbuntuではimage_transferで画像をrawに戻してOpenVSLMAの入力に送っている。JetbotのコントロールはゲームコントローラをホストUbuntuに接続し、ROSのJoyパッケージで操作を行なっている。

Jetson nano上でもOpenVSLAMが動くことは確認したが、GPUを使うわけではないのでJetson nanoで動かす旨味はあまりない。
ROSのインストール
Jetson nano とホスト側のUbuntu環境へROSをインストールする。また、Jetson nano側のROSはPython3でROS Nodeを開発できるように設定を済ませておく必要がある。
Jetbot用ROSパッケージの準備
JetbotへJetbot用のROSパッケージを準備する。以下のリポジトリをJetson nano側のROSワークスペースにクローンしcatkin_makeしておく。
cd ~/your_ros_workspace/src git clone https://github.com/masato-ka/ros_jetbot.git cd ../ catkin_make
image_procパッケージをインストールしていない場合はインストールしておく。
sudo apt-get install -y ros-melodic-image-proc
OpenVSLAMのインストール
ホスト側のUbuntu 18.04へOpenVSLAMをインストールする。以下のページの手順に進めればインストールできる。16.04 testedと書いているが、18.04でも問題なくインストールできる。
ポイントは以下の2つ。
- OpenCVは上記手順通りソースからビルドする
- SocketViewerでインストールする
- SocketViewer用のNode.js環境も構築する。
もちろんPangolinを選択しても問題はないが、それなりのビデオカードが必要になる。
OpenVSLAMのビルドまで完了したらROSパッケージのインストールを行う。こちらも公式の手順通りで問題ない。また、ビルドオプションはSocketViewerを選択する。image_transportパッケージのインストールも忘れずに実施する。
ORB特徴のボキャブラリーファイルをダウンロードする。ちなみに何に使うのかは理解してないのでこの辺りはどっかで調べる。
# download an ORB vocabulary from Google Drive
cd /path/to/openvslam/build/
FILE_ID="1wUPb328th8bUqhOk-i8xllt5mgRW4n84"
curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=${FILE_ID}" > /dev/null
CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
curl -sLb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=${FILE_ID}" -o orb_vocab.zip
unzip orb_vocab.zip
またカメラパラメータのファイルを作っておく。Jetbotに使う広角レンズ(SainSmart IMX219)の場合
cd /path/to/openvslam/build/ vi jetbot_mono.yaml
でjetbot_mono.yamlを新規作成する。記載内容は以下の内容を記載する。
#==============# # Camera Model # #==============# Camera.name: "Jetbot" Camera.setup: "monocular" Camera.model: "perspective" Camera.fx: 1138.042594 Camera.fy: 1152.150891 Camera.cx: 314.573090 Camera.cy: 273.959896 Camera.k1: -2.663941 Camera.k2: 5.967979 Camera.p1: -0.053529 Camera.p2: 0.031916 Camera.k3: 0.0 Camera.fps: 5.0 Camera.cols: 640 Camera.rows: 480 Camera.color_order: "RGB" #================# # ORB Parameters # #================# Feature.max_num_keypoints: 2000 Feature.scale_factor: 1.2 Feature.num_levels: 8 Feature.ini_fast_threshold: 20 Feature.min_fast_threshold: 7
カメラが違う場合はcamera_calibration パッケージを利用してキャリブレーションをする。
実行
Jetbot側の準備
JetbotのROSモジュールを実行する。
export ROS_MASTER_URI=http://[Jetbot IP]:11311 export ROS_IP=[Jetbot IP] roslaunch ros_jetbot jetbot.launch
ホスト側の準備
Jetbotコントロール用のjoy_nodeの立ち上げ
export ROS_MASTER_URI=http://[Jetbot IP]:11311#JetbotのIPを指定する export ROS_IP=[Ubuntu IP]#Ubuntu VMのIP rosparam set joy_node/dev [ゲームパットのデバイスパス] rosrun joy joy_node
image_transportモジュールの起動
export ROS_MASTER_URI=http://[Jetbot IP]:11311#JetbotのIPを指定する export ROS_IP=[Ubuntu IP]#Ubuntu VMのIP rosrun image_transport republish compresin:=/jetbot/image_color raw out:=/camera/image_raw
Viewersサーバの起動
cd /path/to/openvslam/viewer node app.js
OpenVSLAM ROSモジュールを起動
export ROS_MASTER_URI=http://[Jetbot IP]:11311 export ROS_IP=[Jetbot IP] rosrun openvslam run_slam -v /path/to/openvslam/build/orb_vocab/orb_vocab.dbow2 -c /path/to/openvslam/build/jetbot_mono.yaml
実行結果の確認
http://[Ubuntu IP]:3001にアクセスするとOpenVSLAMの実行結果を確認することができる。

- 動画
動画だと実験環境のネットワークコンディションのせいでカクカクしているがもう少しスムーズに動く。また、途中でロストしているが、再度ローカライゼーションに成功している。
まとめ
Jetson nanoのGPUを使っていないので、あまりうまみはないが、ローカライゼーションさせれば何か面白いことができるかもしれない。CNN SLAMなどDNNを使ったSLAMを使うと状況が違うのかもしれない。